Unity粒子系统
Unity有两套粒子系统
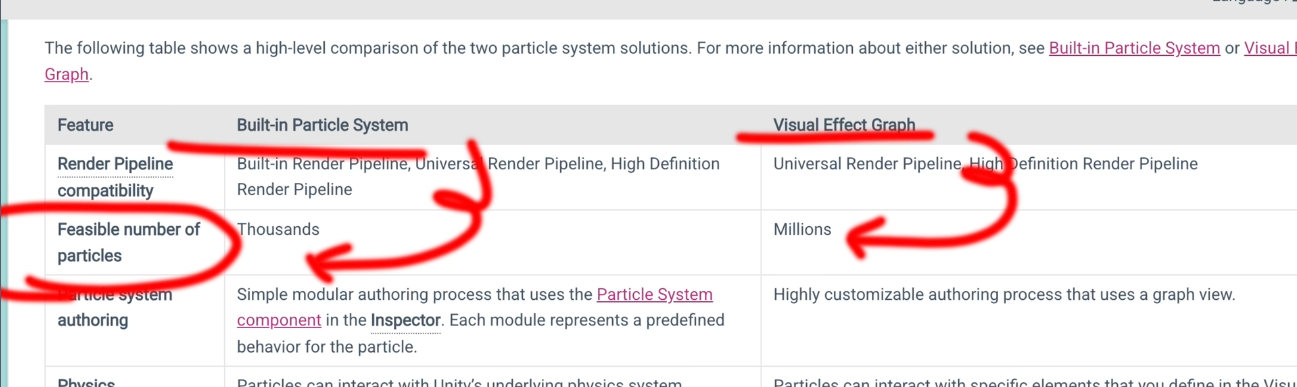
CPU粒子的ParticleSystem,能支撑粒子的数量级是几千个
GPU粒子的Visual Effect Graph(VFX Graph),能支撑粒子的数量级是几百万个
粒子是什么
从编程角度来看
数据:
结构体,必须有一个Vector3的Position属性
其他属性,可以有Color、Scale
假设有一个例子系统,由10万个这样的粒子构成
1 2 3 4 5 6 7 8 struct Particle{ Vector3 Position; ... } Particle[] particles = new Particle[100000 ];
逻辑:
根据某种规律,每一帧,计算position属性,让这些数据“运动”起来
1 2 3 4 5 6 7 8 9 10 11 class Particle { update(float dt) { foreach (var p in _particles) { p.position = ... ... } } }
表现:
如何结合图像API把刚才10万个粒子的数据展示出来,比如把每个例子渲染成点图元、面片等
CPU粒子和GPU粒子的实现有很大区别 CPU粒子
工作流程:
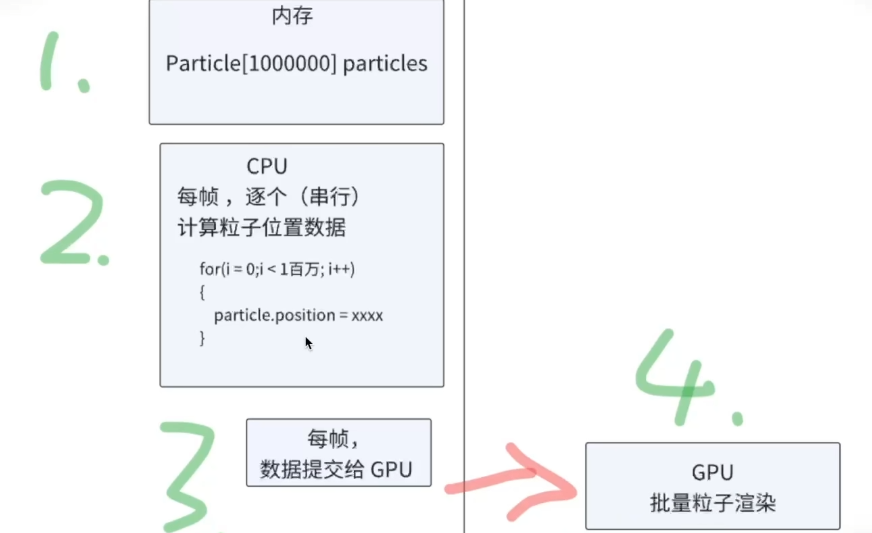
第一步:在内存里初始化10万个粒子对象
第二步:每一帧里更新十万个粒子的位置
第三步:每一帧要把变换的数据提交给GPU,让GPU做渲染
开销影响:
由于第二步的计算每一帧都要计算,而CPU无法进行并行计算,所以粒子数量多时,计算开销非常大
第三步数据计算之后,需要从CPU把计算的结果提交给GPU做显示,这样的显示每一帧都要做,都涉及到跨CPU和GPU的通信
GPU粒子
工作流程:
第一步:虽然也需要声明10w万个粒子的数据,但是会在初始化的时候,一次性的把这些数据从内存拷贝到GPU显存侧的ComputeBuffer里
第二步:计算每一个粒子下一帧所应该在的位置,计算后的结果依然存储在GPU的显存的ComputeBuffer里面
第三步:渲染的时候直接从显存的ComputeBuffer里面拿数据,直接渲染
开销影响:
第二步由于发生在GPU侧,可以充分利用GPU里面的ComputeShader并行计算能力
第三步减少了CPU到GPU的数据拷贝
借助ComputeShader和ComputeBuffer实现GPU粒子的细节
数据
需要一个结构体particle,里面至少要包含一个Position属性
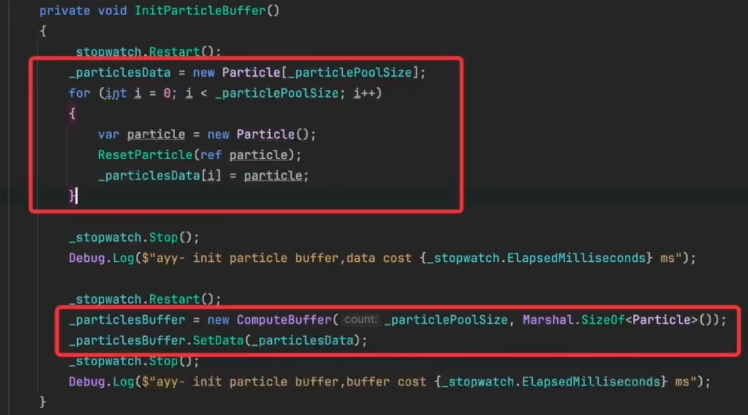
初始化数据,初始化ComputeBuffer,填充数据
把结构体数据填充到内存里,并拷贝到ComputeBuffer里
new ComputeBuffer()
第一个参数是要缓存多少个这样的粒子,ComputeBuffer的长度要和粒子的长度一样
第二个参数是Particle结构体的大小
new完后只是说显存里有这个Buffer了,还要把数据真正拷贝过去
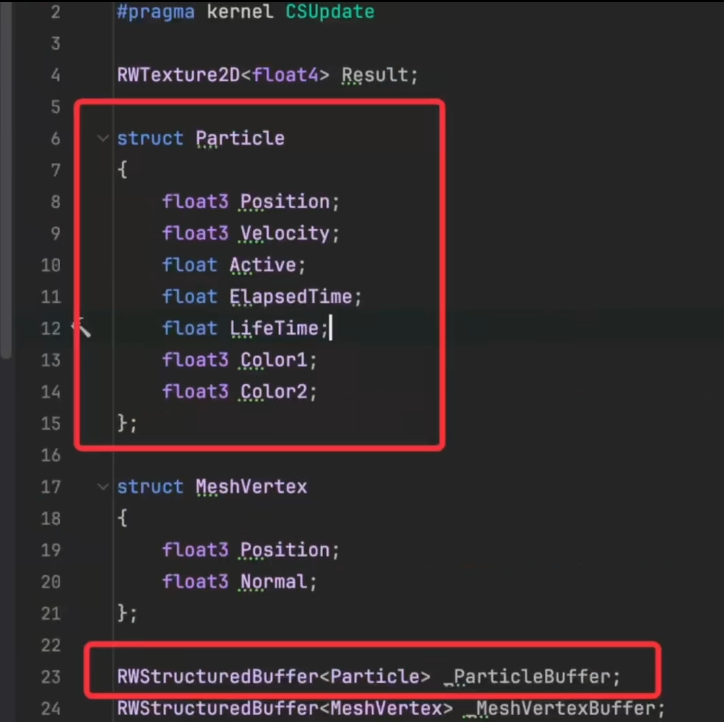
为了能在ComputeShader计算的时候能使用上刚才ComputeBuffer里的数据,需要新建一个ComputeShader,也写上一个同样的struct
写一个RWStructure的Buffer,把Particle当做泛型传进来,相当于准备好一个Particle List去容纳CPU传过来的数据
在C#里准备好了ComputeBuffer、在ComputeShader里准备好了StructureBuffer之后,需要把二者关联起来
逻辑
变成GPU粒子后,Update函数有比较大的变化
不会在Update里面做for循环了,只需要给ComputeShader设置deltaTime,然后调用Dispatch,传一个ComputeShader的函数名,这样ComputeShader就会去工作,自动去算每个粒子的位置了
实践
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 using System.Collections;using System.Collections.Generic;using UnityEngine;public class ComputeShader2 : MonoBehaviour { struct Particle { public Vector3 Position; public Vector4 Color; } private Particle[] particleData; [SerializeField ] private int particleCnt = 1000 ; private ComputeBuffer particleBuffer; private void Start () { InitParticleData(); } #region Init Particle Data private void InitParticleData () { particleData = new Particle[particleCnt]; for (int i = 0 ; i < particleCnt; i++) { var particle = new Particle(); ResetParticle(ref particle); particleData[i] = particle; } particleBuffer = new ComputeBuffer(particleCnt, (4 + 3 ) * sizeof (float )); particleBuffer.SetData(particleData); } private void ResetParticle (ref Particle particle { particle.Color = Color.white; particle.Position = Vector3.zero; } #endregion }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #pragma kernel CSMain RWTexture2D<float4> Result; struct Particle { float3 position; float4 color; }; RWStructuredBuffer<Particle> ParticleBuffer; [numthreads(8,8,1)] void CSMain (uint3 id : SV_DispatchThreadID) { Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0); }
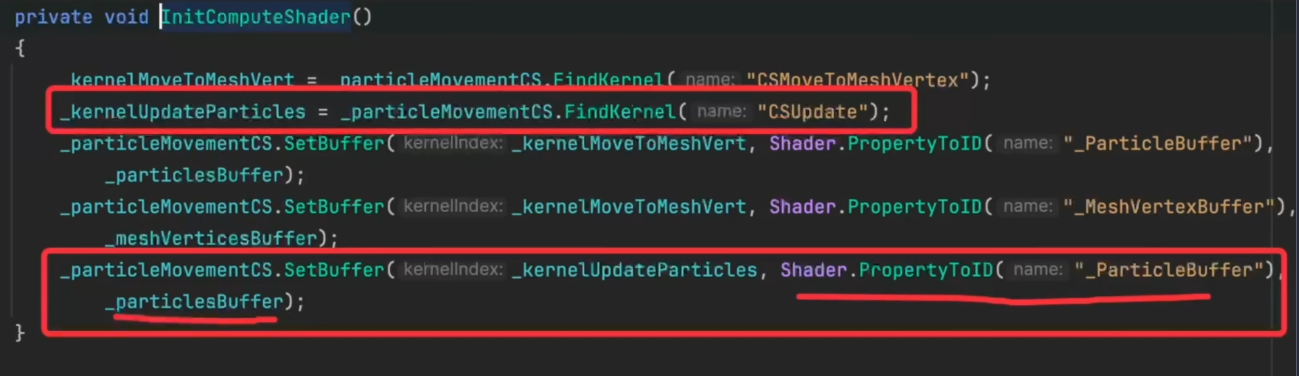
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [SerializeField ] private Material material; [SerializeField ] private ComputeShader particleCS; private int kernelUpdateParticleHandle;private void Start (){ InitParticleData(); InitComputeShader(); } private void InitComputeShader (){ kernelUpdateParticleHandle = particleCS.FindKernel("UpdateParticle" ); particleCS.SetBuffer(kernelUpdateParticleHandle, "ParticleBuffer" , particleBuffer); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #pragma kernel UpdateParticle RWTexture2D<float4> Result; struct Particle { float3 position; float4 color; }; RWStructuredBuffer<Particle> ParticleBuffer; [numthreads(8,8,1)] void UpdateParticle (uint3 id : SV_DispatchThreadID) { Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0); }
1 2 3 4 5 private void Update (){ particleCS.SetFloat("Time" , Time.time); particleCS.Dispatch(kernelUpdateParticleHandle, Mathf.CeilToInt((float )particleCnt / 64 ), 1 , 1 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #pragma kernel UpdateParticle RWTexture2D<float4> Result; struct Particle { float3 position; float4 color; }; RWStructuredBuffer<Particle> ParticleBuffer; float Time; [numthreads(64,1,1)] void UpdateParticle (uint3 id : SV_DispatchThreadID) { int particleIndex = id.x; Particle parti = ParticleBuffer[particleIndex]; float3 pos = parti.position; parti.position = pos + Time * float3(1, 0, 0); ParticleBuffer[particleIndex] = parti; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 Shader "Unlit/CS2" { Properties { _MainTex ("Texture", 2D) = "white" {} } SubShader { Tags { "RenderType"="Opaque" } LOD 100 Pass { CGPROGRAM #pragma vertex vert #pragma fragment frag #include "UnityCG.cginc" struct Particle { float4 color; float3 position; }; struct v2f { float4 color : TEXCOORD0; float4 vertex : SV_POSITION; }; sampler2D _MainTex; float4 _MainTex_ST; StructuredBuffer<Particle> _particleBuffer; v2f vert (uint id : SV_VertexID) { v2f o; o.vertex = UnityObjectToClipPos(fixed4(_particleBuffer[id].position, 0)); o.color = _particleBuffer[id].color; return o; } fixed4 frag (v2f i) : SV_Target { return i.color; } ENDCG } } }
1 2 3 4 5 private void Update (){ material.SetBuffer("_particleBuffer" , particleBuffer); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [numthreads(64,1,1)] void UpdateParticle (uint3 gid : SV_GroupID, uint index : SV_GroupIndex) { int pindex = gid.x * 64 + index; float x = sin(index); float y = sin(index * 1.2f); float3 forward = float3(x, y, -sqrt(1 - x * x - y * y)); ParticleBuffer[pindex].color = float4(forward.x, forward.y, cos(index) * 0.5f + 0.5, 1); if (Time > gid.x) { ParticleBuffer[pindex].position += forward * 0.005f; } }